Introduction
1. Introduction
What is Amazon S3?
Amazon Simple Storage Service (Amazon S3) is a leading object storage service known for its scalability, high availability, and strong security. It supports diverse use cases, such as data lakes, websites, mobile applications, backups, disaster recovery, and big data analytics.
What are Amazon S3 Tables?
Amazon S3 Tables introduce the first cloud object storage solution with built-in support for Apache Iceberg. S3 Tables streamline storing and managing structured, tabular data at scale, offering significant optimization and performance enhancements.
How Amazon S3 Tables Work
Purpose-Built Storage for Tabular Data
S3 Tables are specifically designed for storing structured data in the Apache Parquet format, providing better data organization and analytics performance.Automated Data Optimization
S3 Tables automatically optimize stored data by compacting Parquet objects. This compaction process enhances query performance and reduces storage costs.
Benefits of Amazon S3 Tables
Outstanding Scalability
Simplify data lake management at any scale, from small projects to operating thousands of tables in Iceberg environments.Enhanced Performance
Achieve up to 3x faster query speeds through continuous table optimization compared to unmanaged Iceberg tables, and up to 10x higher transaction throughput than Iceberg tables stored in standard S3 buckets.Fully Managed Service
Automatically handles maintenance tasks such as compaction, snapshot management, and removing unreferenced files to optimize query efficiency and long-term costs.Seamless Integration
Leverage advanced Iceberg analytics capabilities with familiar AWS services like Amazon Athena, Redshift, and EMR, while maintaining compatibility with popular open-source tools.Simplified Security
Manage tables as first-class AWS resources, allowing you to easily apply permissions and govern access securely.
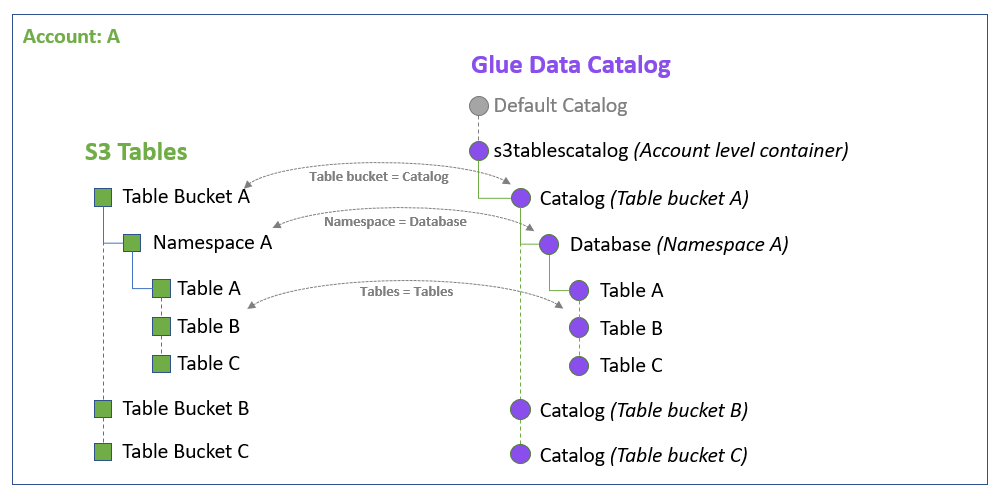
Key Components of S3 Tables
- Table Buckets: Special S3 buckets designed to store analytical data, supporting Iceberg-managed tables with various schemas.
- Tables: Structured datasets organized in table buckets. These tables include features like automatic compaction, unreferenced file cleanup, and snapshot management.
- Namespaces: Logical groupings of tables within a bucket, enabling efficient data organization and classification.
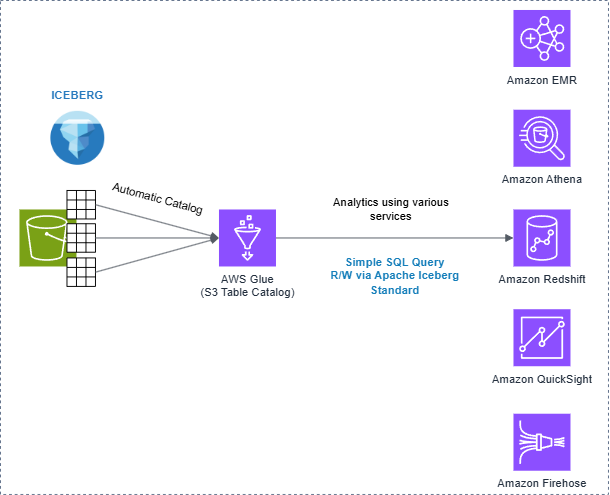
AWS Glue Data Catalog
AWS Glue Data Catalog serves as a centralized metadata repository that stores information about data locations, schemas, and runtime parameters. Acting as an index, it simplifies querying and can be registered as a data source in Lake Formation.
Glue Data Catalog seamlessly integrates table buckets, namespaces, and tables into metadata objects, making data management efficient and user-friendly.
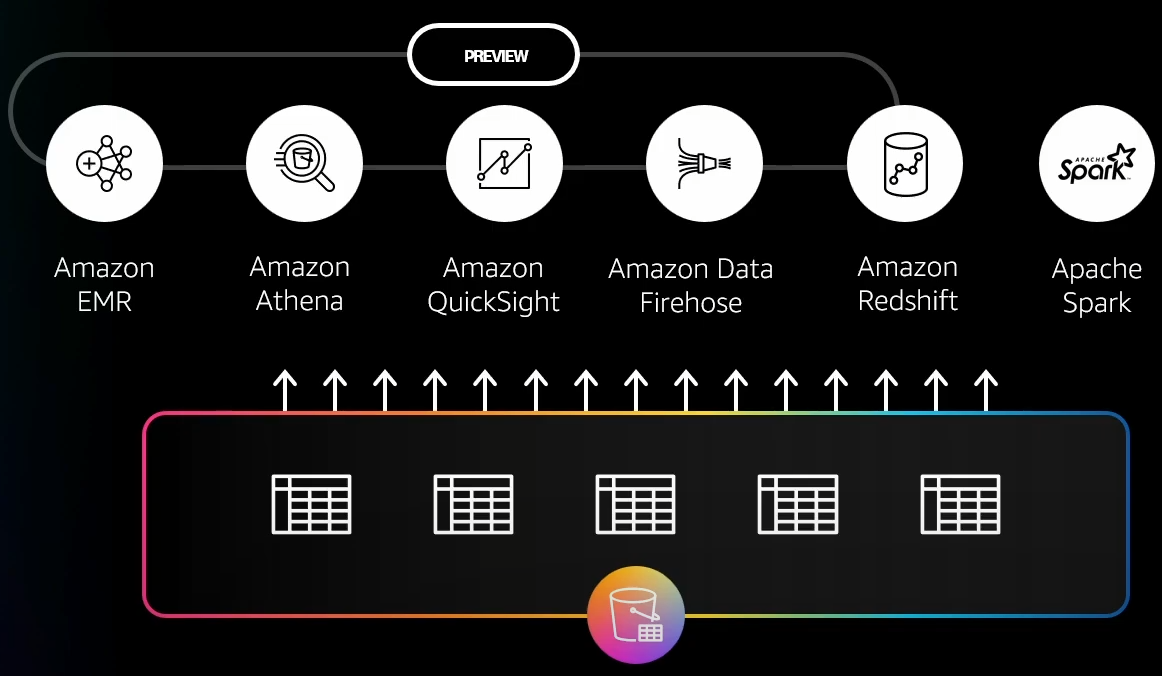
AWS Analytics Services Integrated with S3 Tables
- Amazon Athena: A serverless SQL query service to directly interact with S3 without requiring any infrastructure setup.
- Amazon Redshift: A petabyte-scale data warehouse for efficient analytics, with Redshift Serverless enabling access without complex configurations.
- Amazon EMR: A big data platform that supports frameworks like Apache Hadoop and Spark for large-scale data processing.
- Amazon QuickSight: A data visualization tool offering dynamic dashboards, supported by the scalable SPICE Engine for fast performance.
- Amazon Data Firehose: A real-time streaming data service integrated with S3, Redshift, OpenSearch, and Iceberg Tables.