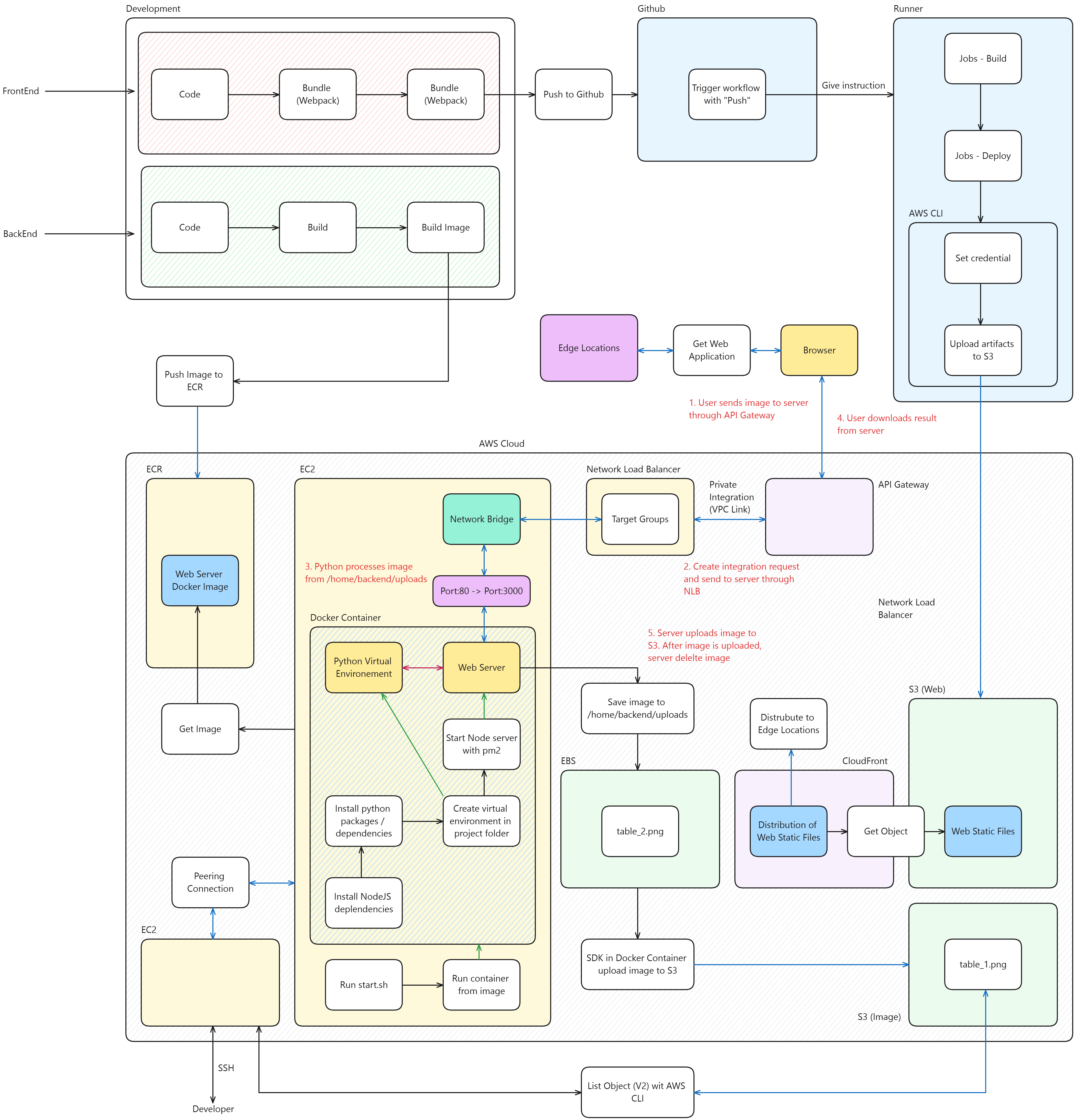
Auto deployment and installation
You can skip this section and move on to the next parts. However, if you want to understand how the system is deployed, please continue reading this section.
In the development environment, there are two parts: FrontEnd and BackEnd.
Deploying the website
In our development environment, the website will be deployed through the following steps:
- The complete version of the website is uploaded to S3.
- CloudFront retrieves the website data from the S3 Bucket (referred to as Origin). A distribution is created to manage this data.
- However, this Bucket is private, so CloudFront needs to configure OAI to set it in the Bucket’s resource-based policy, allowing the Bucket to “know” the distribution.
- CloudFront will then distribute the data to different Edge Locations.
- When users access the web application, the browser will fetch information from the nearest Edge Location.
- Finally, the content is displayed to the end users.
Typically, to deploy a web application, you need to build -> test -> deploy to the server (upload the web application data) manually.
But in this case, our application will be deployed automatically with Github Actions. Specifically, Github triggers a workflow when the main branch of the project is pushed from a developer’s machine or merged from other branches, or a developer can trigger it manually.
At that point, a Runner will handle the tasks (Jobs) in the workflow, executing predefined steps (Steps), specifically:
- The web content will be bundled by Webpack.
- Then, unnecessary characters will be minimized to reduce the size.
- The content is saved into a directory (build).
- AWS CLI is set up with credentials from the ACCESS KEY ID and SECRET ACCESS KEY, along with the Bucket name and Region.
- AWS will copy the contents from the (build) directory and upload them to S3.
- Finally, the tasks are finished, and the Runner cleans up resources.
Here’s the workflow.
# Name of flow
name: Deploy to product environment
# The event of github
# When should it (workflows) run?
on:
# Push changes in source code to master or main
push:
branches: [master, main]
concurrency:
group: "pages"
cancel-in-progress: false
defaults:
run:
shell: bash
jobs:
build_website:
runs-on: ubuntu-latest
steps:
# Check out to repository
- name: Check to repository
uses: actions/checkout@v4
with:
submodules: recursive
# Install NODEJS
- name: Install NodeJS
uses: actions/setup-node@v4
with:
node-version: 20
# Install dependencies
- name: Install dependencies
run: npm install
# Build website with webpack
# The directory is build/gui
- name: Build website
run: npm run build
# Prepare AWS Credential
- name: Prepare AWS Credential
uses: aws-actions/configure-aws-credentials@v4
with:
aws-access-key-id: ${{ secrets.AWS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY}}
aws-region: ${{ secrets.AWS_REGION}}
# Upload S3
- name: Upload website to Amazon S3
run: aws s3 cp ./build/gui s3://${{ secrets.AWS_BUCKET }} --recursive
Overall, this workflow adequately captures everything I want to convey. Additionally, you can split the build and deploy steps (from preparing AWS credentials to uploading the artifact to S3) into two separate jobs. Even though each job will run on a different runner, they will still be part of the same workflow. Therefore:
- At the end of the build job, you should upload the artifact to the workflow context.
- At the start of the deploy job, download the artifact to the runner and proceed with the remaining steps.
Deploying the web application’s server
Deploying the server for the web application is slightly more complex, as we need to write a deployment script in a Docker container. The deployment flow is as follows:
- After development, the web server’s source code will be built using Docker through scripts.
- Once packaged into a Docker Image, it will be uploaded to ECR.
- At this point, the DevOps engineer will connect to the EC2 instance in the production environment to pull the Docker image from ECR.
- Next, Docker will be run to begin the deployment.
Specifically, during the build process:
- Node and Npm will be installed to set up the required libraries for running the Node Server.
- Python and Pip will be installed to perform the core functions.
- Python libraries and Tesseract OCR will also be installed.
For the corresponding build process, we have two scripts. These scripts will be executed during the Docker container build:
Install NodeJS and required packages for Web server
The first file script is backend/nodejs/scripts/install.sh
This script is used to install the necessary packages to deploy the web server application.
#!/bin/bash
. /home/backend/utils.sh
## Update packages
apt update
## Install curl
apt install curl
## Install nodejs
### Install `nvm`
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.0/install.sh | bash
export NVM_DIR="$HOME/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
[ -s "$NVM_DIR/bash_completion" ] && \. "$NVM_DIR/bash_completion" # This loads nvm bash_completion
# infoln "NVM has just been installed: $(nvm -v)"
### Install node 20
nvm install node 20
### Check version of `node` and `npm`
infoln "Node has just been installed: $(node -v)"
infoln "NPM has just been installed: $(npm -v)"
### Change directory to `nodejs`
cd /home/backend/nodejs
## Install packages in `package.json`
npm install
npm install -g pm2
infoln "Install packages: $(npm list -g)"
Explanation:
- First, load the utilities in
/home/backend/utils.sh. These utilities are functions used for displaying output to the screen. - Update the package information in the system with
apt update. - Install
curland download nvm using curl, then executeinstall.shwith thebashcommand. - After installation, start setting up the environment variables.
- Install Node.js version 20.
- Globally install
pm2, which is used to manage Node.js instances.
At this point, we won’t start the server yet because the backend is not ready to run.
Install Python, Tesseract OCR
The next script is backend/python/scripts/install.sh
This script is used to install Python libraries as well as Tesseract OCR.
#!/bin/bash
## Update packages
apt update
## Install util packages
apt install wget
## Install python and pip
### Install python3
apt install python3
printf "Python has been just installed: $(python3 --version)"
### Install `pip3` and `virtualenv`
apt install python3-pip python3-virtualenv
printf "PIP has just been installed: $(pip3 --version)"
printf "virtualenv has just been installed: $(virtualenv --version)"
# Change directory to `/home/backend/python`
cd /home/backend/python
## Create virtual environment
virtualenv venv
source venv/bin/activate
## Install packages in `requirements.txt`
pip3 install -r requirements.txt
## Install tesseract
apt install tesseract-ocr
## Create `xml/haarcascade` directory
mkdir xml
cd xml
mkdir haarcascade
cd haarcascade
## Install xml file for test
wget https://raw.githubusercontent.com/opencv/opencv/4.x/data/haarcascades/haarcascade_frontalface_default.xml
wget https://raw.githubusercontent.com/opencv/opencv/4.x/data/haarcascades/haarcascade_eye_tree_eyeglasses.xml
Explanation:
- Similar to the previous script, we should update the package information.
- Install
wget. - Install Python 3 using
apt install python3. - Typically, when installing Python on Linux,
pipisn’t included, so we also installpython3-pipandvirtualenv. Virtualenv allows us to isolate Python resources on the machine. - After installation, change directory to
/home/backend/python(the root of the Python application). - Create a virtual environment with
virtualenv, using the foldervenvas the environment directory. Then, activate the virtual environment by runningsource venv/bin/activate. - Now, install the required Python libraries listed in the
requirements.txtfile. - Install Tesseract OCR with
apt. - Since we are in the root directory of the Python application, create a new folder named
xml. Change directory into this folder, then create another folder namedhaarcascadeand navigate into it. - Download the XML training files to support face and eye recognition. This step can be skipped as it’s not part of the core functionality, but if you want to test it in the future, you can keep it.
At this point, the Python application is ready to run.
Start up web server
Another script is used to start the server: backend/nodejs/scripts/start.sh
#!/bin/bash
# Set up PATH
export NVM_DIR="$HOME/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
[ -s "$NVM_DIR/bash_completion" ] && \. "$NVM_DIR/bash_completion" # This loads nvm bash_completion
# Change directory to `nodejs`
cd /home/backend/nodejs
export PYTHON_PATH="/home/backend/python/venv/bin/python"
export TEMP_PATH="/home/backend/temp"
export UPLOADS_PATH="/home/backend/uploads"
## Setup AWS Resource Information
export AWS_REGION="your_region"
export BUCKET_NAME="your_bucket_name"
# Start NodeJS Server
npm start
pm2 logs
Explanation:
- Since each script is a separate subprocess, environment variables set in one script will disappear when moving to another. Therefore, environment variables for running Node, Nvm, and Npm need to be reassigned.
- Then, assign other environment variables that will be used in the Node.js application.
- Two important environment variables are
AWS_REGIONandBUCKET_NAME, representing the region where the S3 bucket is deployed and the name of the bucket, respectively. This bucket will be used to store images. - Start the server and open the logs.
At this point, everything is almost ready. Now, we can combine the individual scripts into one unified script for deployment.
Combine all scripts
Finally, they are combined into a single script: backend/install.sh
#!/bin/bash
. utils.sh
# Change directory to `backend`
infoln "Change directory to /home/backend"
cd /home/backend
# Install NodeJS Server
infoln "Installing NodeJS Dependencies..."
bash nodejs/scripts/install.sh
infoln "Done!"
# Change directory to `backend`
cd /home/backend
# Install Python
infoln "Installing Python Packages, Tesseract OCR..."
bash python/scripts/install.sh
infoln "Done!"
# Change directory to `backend`
cd /home/backend
# Create `temp` and `uploads` folders
infoln "Create \`temp\` and \`uploads\` folders..."
mkdir temp
mkdir uploads
infoln "Done!"
# Start server
infoln "Booting server..."
bash nodejs/scripts/start.sh
infoln "Done!"
You won’t need to install these scripts in this exercise, as they have already been installed in the source code.
Summary, the deployment strategy of our applications looks like this: